Google recently released a paper detailing how it has designed and deployed ESPRESSO: the SDN at the edge of its network. The paper was published at SIGCOMM’17. In the past, Google’s SDN papers have been very insightful and inspiring, so I had big expectations for this one as well.
In this blog post, I’ll summarize and highlight the main points of the paper. I’ll follow-up with some conjectures on what we can abstract from the paper in terms of industry trends and understand the state-of-the-art SDN technologies.
For reference, Google has released several papers detailing its networking technologies, these are the most important ones:
- B4 detailed Google’s SDN WAN – A must read. It explains how they drastically increased network utilization by means of global traffic engineering controller.
- Jupiter Rising details hardware aspects of data center networks.
- BwE explains Google’s bandwidth enforcer that plays a huge role in traffic engineering.
B4 connects Google’s Data Centers, B2 is the public facing network, which connects to ISPs in order to serve end-users. Espresso, an SDN infrastructure deployed at the edge of B2 enabled higher network utilization(+13%) and faster networking service roll-out.
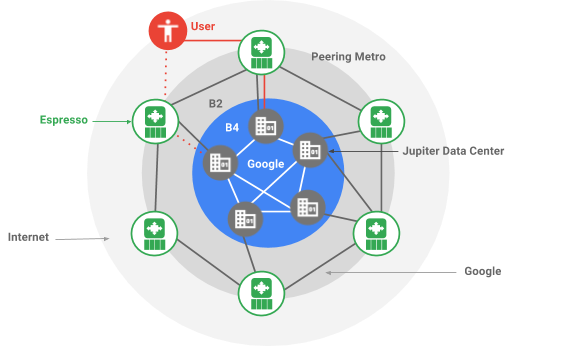
Requirements and Design Principles
The basic networking services provided at the edge are:
- Peering – Learning routes by means of BGP
- Routing – Forwarding packets. Based on BGP or TE policies
- Security – Blocking or allowing packets based on security policies
To design the system, the following requirements were taken into account:
- Efficiency – capacity needs to be better utilized and grow cheaply
- Interoperability – espresso needs to connect to diverse environments
- Reliability – must be available 99.999% of the time
- Incremental Deployment – green-field deployment only is not compelling enough
- High Feature Velocity
Historically, we have relied on big routers from Juniper or Cisco to achieve these requirements. Those routers usually would have the full internet routing table stored, as well as giant TCAM tables for all ACL rules needed to protect THE WHOLE INTERNET, and those are quite expensive. More importantly, a real Software-Defined Network allows you to deliver innovation at the speed of software development rather than the speed of hardware vendors.
Basically, 5 design principles are applied in order to fulfill those requirements:
- Software Programmability – OpenFlow-like Peering fabric
- Testability – Loosely coupled components allow software practices to be applied.
- Manageability – Large-scale operations must be safe, automated and incremental
- Hierarchical control plane – Global and local controllers with different functions allow the system to scale
- Fail-static – Data plane maintains the last known good state to prevent failures in case of control plane unavailability
Peering Fabric
The Peering Fabric provides the following functions:
- Tunnels BGP peering traffic to BGP Speakers
- Tunnels End user requests to TCP reverse proxy hosts
- Provides IP and MPLS based packet forwarding in the fabric
- Implements a part of the ACL rules
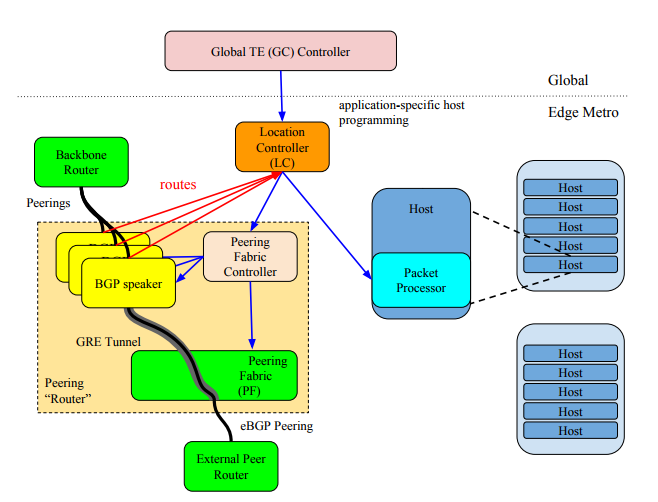
All the magic happens in the hosts. First, the BGP speakers learn the neighbor routes and propagate those to the local controller (LC), which then propagates those to the global controller(GC). The GC then builds its intent for optimal forwarding of the full internet routing table. It then propagates those routes to LCs which then install them in all the TCP reverse proxy hosts. The same thing happens for security policies.
The BGP Speakers are in fact a Virtual Network Function, which is a network function implemented using x86 CPUs, the routing also is a VNF, as well as ACLs. Also, notice that the peering fabric is not complicated at all. The most used ACL rules(5%) are there but the full Internet Routing table is not. The hosts will make the routing decision and encapsulate the packets, labeling it with the egress switch and egress port of the Fabric.
Configuration and Management
It’s mentioned in the paper that as the LC propagates configuration changes down, it canaries those changes to a subset of nodes and verify correct behavior before proceeding to wide-scale deployment. These features are implemented:
- Big Red Button – the ability to backroll features of the system and test this nightly.
- Network Telemetry – monitors peering link failure and route withdrawals.
- Dataplane Probing – End-to-end probes monitor ACL – unclear if OF is used for this
Please refer to the original paper for details. I hope this post is useful for you and I apologize for any miscommunication. At the end of the day, I’m writing this post to myself more than anything.
Feature and rollout velocity
Google has achieved great results in terms of feature and rollout velocity. Because it’s software-defined they can leverage their testing and development infrastructure. Along three years Google has updated Espresso’s control plane >50x more frequently compared to traditional routers, which would have been impossible without the test infrastructure.
The L2 private connectivity solution for cloud customers was developed and deployed in a few months. Without new hardware or need for waiting vendors to deliver new features. Again something unimaginable with legacy network systems. In fact, they state the same work on the traditional routing platform is still ongoing and has already taken 6x longer.
Traffic Engineering
To date, Espresso carries at least 22% of outgoing traffic. The nature of GC allows them to serve traffic from a peering point to another. The ability to make this choice by means of Espresso allows them to serve 13% more customers during peaks.
Google caps loss-sensitive traffic to prevent errors in bandwidth estimation. Nonetheless, GC can push link utilization to almost 100% by transmitting lower QoS, loss-tolerant traffic.
Conclusion
From the paper: “Espresso decouples complex routing and packet processing functions from the routing hardware. A hierarchical control-plane design and close attention to fault containment for loosely-coupled components underlie a system that is highly responsive, reliable and supports global/centralized traffic optimization. After more than a year of incremental rollout, Espresso supports six times the feature velocity, 75% cost-reduction, many novel features and the exponential capacity growth relative to traditional architectures.
Be First to Comment