“90% of coding is debugging, the other 10% is writing bugs.”
If you develop any code you know how true this is. This implies the speed you correct bugs is what really dictates your feature release velocity. This relates to a critical part of DevOps: CI/CD. Continues Integration allows bugs to be found faster, continuous deployment allows fixes to be released in production faster.
In this post, I talk about the importance of a stable Developer Environment (Dev Env) and present a short tutorial on how to set up a virtual routing environment with open source tools provided by Cumulus.
Why bother at all?
A DevEnv to test your automation scripts is essential for any effective development team. It allows devs to test their code in minutes rather than days independently of others, increasing their velocity drastically. It also improves collaboration, by making sure all devs are starting from the same stable point.
Here is an example of how bad this is: Company ABC only has one testing environment in which it performs all testing. Say a good scheduling process allows for 50% utilization, and each dev takes 1 hour to run a script and verify its outcome and an additional hour to clean-up the environment. A work day has 8 hours, where 4 hours are utilized, and thus only 2 tests can be performed per day. In this case, no matter how big your team is, you can only push a total of 2 features or fixes per day. This is pretty much a fixed cap on the team productivity.
Technology choices
I’ve been wanting to set up a virtual environment for a while. At first, I tried using Mininet, while it suffices for routing using quagga, it required too much work to set it up in a way I could use it for testing scripts. The other options were eve-ng(uNetLab), GNS3 and vagrant. I crossed GNS3 right away because the overhead and learning curve are significant. If I had to run IOS I’d go for eve-ng, but I don’t. Additionally, the learning curve for vagrant was shorter thus it’s useful to more people.
Kudos to Cumulus for open-sourcing this, it is great to see vendors contributing multi-purpose code rather than just taking code from others or promoting their own technologies and I urge you to check their work. You can start from here.
Quick start
Disclaimer: this code is available at the cumulus GitHub. Before running this demo, install VirtualBox and Vagrant.
### Bring up the vagrant topology
git clone https://github.com/cumulusnetworks/cldemo-vagrant
cd cldemo-vagrant
vagrant up oob-mgmt-server oob-mgmt-switch leaf01 leaf02 spine01 spine02 server01 server02
### setup oob mgmt server
vagrant ssh oob-mgmt-server
### Run the ROH demo
git clone https://github.com/cumulusnetworks/cldemo-roh-ansible
cd cldemo-roh-ansible
ansible-playbook run-demo.yml
### check reachability of server02 from server01
ssh server01
wget 10.0.0.32
cat index.html
Custom topology
You only need vagrant, Virtualbox and git to run this tutorial. Vagrant is really simple, once you have a vagrantFile, you need exactly one line of code to bring your environment up. The tricky part is to build the Vagrant File, Cumulus not only provides the templates but also a tool to create the file from a topology file. It’s the topology converter.
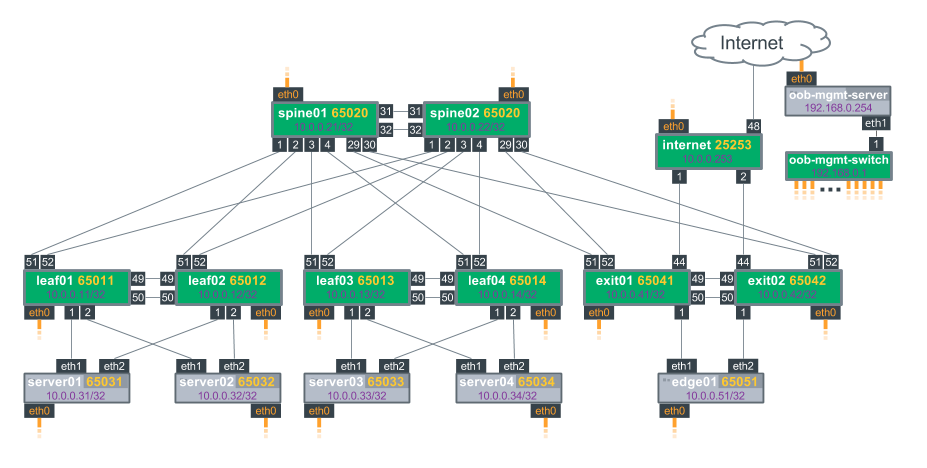
The figure above shows the default topology, you can change it by editing the topology file and then run the topology_converter again:
python topology_converter.py topology.dot
After that simply do. Vagrant up and boom.
vagrant up
vagrant ssh oob-mgmt-server
Conclusion
In this post, I talked about the importance of a stable developer environment and how that fits into the DevOps framework. I also gave an example of how to establish an environment.
This links back to the SDN value proposition: the ability to run software processes to improve your infrastructure. But, people have virtualized network devices for years, there’s nothing new there. True, still, a significant part of network operators does not have a virtual environment in order to test their systems. On the other side, with the rise of OpenVSwitch and creation of Mininet, SDN developers started using network emulation to develop SDN systems and have always taken this as a given yielding increased development agility.
This also leads me to some thoughts on how P4 can improve enterprise systems, but I’ll leave that for a future post. Again, please let me know your thoughts on this

